Cas d'usage
Forensique & eDiscovery
La technologie linguistique avancée de SYSTRAN rationalise les process d'eDiscovery en traitant de manière efficace et sécurisée d'énormes volumes de données. Cela permettra à vos équipes de surmonter les barrières linguistiques tout en fournissant des informations précieuses pour les affaires juridiques transfrontalières et les analyses forensiques.
Ils nous font confiance


Bénéfices
Faciliter l'eDiscovery grâce Traduction automatique
Analyser de grandes quantités de données provenant de différentes sources et dans plusieurs formats peut devenir complexe dans le contexte des affaires internationales. Les barrières linguistiques peuvent en effet dissimuler des éléments de preuve cruciaux. Il n'est en outre pas souvent envisageable de compter uniquement sur des agences de traduction avant l'analyse des données en raison des délais souvent très courts, associés aux processus d'investigation.
L'efficacité est cruciale pour vos équipes. L'ambiguïté inhérente aux documents multilingues accroît le risque de passer à côté de détails importants pouvant ainsi compromettre une affaire. S'attaquer à ce défi linguistique est essentiel pour obtenir des résultats.

Bénéfices
Sécurité et conformité des données
Lorsqu'on parle de documents juridiques, il est toujours question de données très sensibles. Vous avez donc besoin d'un logiciel de traduction automatique neuronale robuste capable de fournir des fonctionnalités de sécurité et de protéger adéquatement toutes vos données. Cela est essentiel pour la productivité de vos équipes juridiques et pour l'admissibilité des preuves. Traduire le contenu de votre eDiscovery via une plateforme NMT sécurisée telle que SYSTRAN permet de travailler de manière efficace.
La sécurité et la confidentialité des données sont essentielles dans les cas de forensique et d'eDiscovery. SYSTRAN assure le cryptage de bout en bout et adhère aux meilleures pratiques du secteur pour protéger les informations sensibles pendant le processus de traduction. Vos données d'analyse et d'e-discovery restent protégées et conformes aux exigences réglementaires.
Intégration
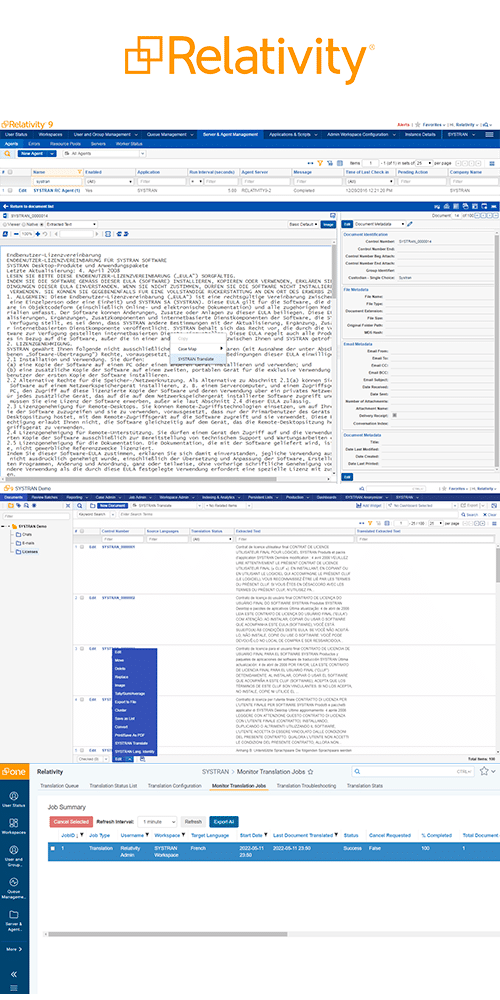
Relativity Connecteur
Une solution de traduction automatique robuste doit faire plus que simplement traduire de larges volumes de données. Elle doit avoir une intégration native avec une plateforme qui traite les données lors de l'eDiscovery. Relativity, une plateforme d'analyse de documents, est le choix privilégié de nombreux professionnels pour traiter du contenu multilingue, en particulier dans des scénarios de litiges.
SYSTRAN a étendu ses capacités en offrant à la fois une traduction automatique on-premise et basée sur le modèle SaaS (Software as a Service) pour RelativityOne.
Ces connecteurs compatibles avec le cloud viennent enrichir le portefeuille déjà existant des connecteurs on-premise de Relativity. Ils facilitent la traduction efficiente des données de eDiscovery en prenant en charge la traduction de données mondialisées. Cette extension confère aux clients de Relativity les avantages en termes de performances, de sécurité, de scalabilité et de flexibilité propres à la technologie cloud.
En relevant les défis engendrés par la croissance de l'information stockée électroniquement (ESI) et l'évolution des normes juridiques, la technologie de SYSTRAN aborde les complexités des documents multilingues tout en assurant la confidentialité des procédures de eDiscovery.
Directeur général, Alvarez & Marsal
"Une raison majeure d'utiliser SYSTRAN était la qualité de l'intégration avec Relativity [...], la rapidité et la précision des traductions étaient en outre impressionnantes par rapport à d'autres éditeurs."
Phil Beckett
Bénéfices
Collaboration accrue & dimension internationale

Intégré avec les outils dont vous avez besoin
SYSTRAN s'intègre facilement à toutes vos applications de travail, permettant une traduction linguistique précise et instantanée. Les équipes peuvent traduire et analyser des volumes massifs de documents en quelques secondes, quel que soit le langage.
SYSTRAN permet à votre marque de résonner dans plus de 55 langues
- Marketing & Publicité
- Traduction de contenu marketing
- Interprétation de conférence
- Traduction de Pitch Book
- Sous-titrage/doublage de vidéo
- Localisation eCommerce
- Interprétation de réunions professionnelles
- Traduction sur les réseaux sociaux
- Localisation de sites web
- Traduction de packagings
- Traduction RFP
- Traduction d'aides à la vente
- Traduction de communiqués de presse
- Traduction de recherche de marché
- Transcréation publicitaire
Comment nous aidons nos clients à l'international


Retrouvez toute l'actualité et les dernières technos de la traduction automatique



Traduction Automatique : Votre Entreprise Contrôle-T-Elle Vraiment Ses Données Sensibles ?
Recherche et traduction automatisée optimisées par l'IA : la parfaite adéquation

La stratégie gagnante pour votre entreprise Traduction automatique : LLM contre IA spécialisée
Rejoignez plus de 1000 entreprises utilisant SYSTRAN
Développez votre entreprise avec SYSTRAN