Take quality and accuracy to the next level
Train engines in your specialty to further improve translation quality
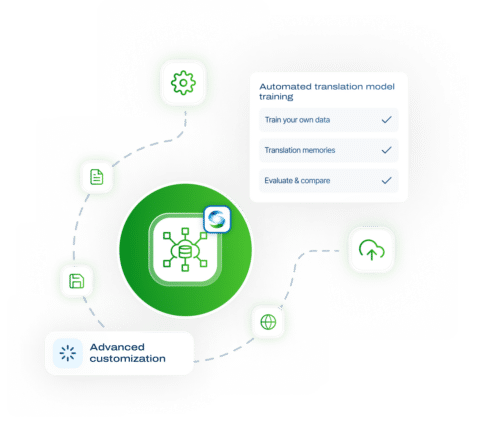
SYSTRAN Model Studio
Create your own translation model
Create your own customized translation model, trained with your own data or your translation memories and increase your translation productivity significantly!

Use your translation memories to adapt your translation model

EVALUATION
Evaluate & compare with the scoring of your model
You can either add your own test set or choose to allocate some of your training data for testing and evaluation during the data upload phase.

Capitalize on SYSTRAN’s extensive catalog
Building a translation model from scratch can be a difficult task. Luckily, you won’t be starting from scratch! As a leader in machine translation for decades, SYSTRAN has built on years of expertise to create an extensive catalog of translation models.
Choose an existing model from the SYSTRAN catalog as a starting point and customize it with your own data. More than 50 languages and dozens of popular domains (Legal, Medical, Finance, IT, etc.) are available!

WEBINAR
Model Studio : Easy, Quick and Customized Translation Model Training
To improve the quality of your translation output, customization is essential, Model Studio is the solution!
In this webinar, Guersande Chaminade, Product Owner and Stéphanie Labroue, Account Manager at SYSTRAN will teach you how to create your own customized translation models with SYSTRAN Model Studio.

CUSTOMIZATION
Providing translations solutions tailored to each industry
Forensics & E-discovery
Big Data Analysis for Law Enforcement
Multilingual Communication & Collaboration
Global Customer Service & Support
Content Localization
FAQ
Find answers to your questions here
If for some reason your question is not here :
What is NFA feature?
NFA, short for Neural Fuzzy Adaptation, is a powerful feature that enables our engine to translate guided by the index. When translators post-edit new segments, the system incorporates these changes on-the-fly, continuously improving the translation quality.
You can learn more about NFA with two of our latests webinar, one with XTM and the other one with MemoQ
Do you only use BLEU score to evaluate Target Languages?
For now, Model Studio displays only the BLEU score. Although we’re actively working on incorporating other tools like Comet, the focus has been on the efficiency and ease of using the BLEU score as our main evaluation metric for the time being.
Can I deploy more than one model simultaneously? SYSTRAN translate Server & SYSTRAN translate Private Cloud ?
Absolutely! You can deploy multiple models and choose the one that best fits your specific project. Before deploying a model, you can also utilize the evaluation feature, which allows you to upload and compare various test files to see how each model performs.
You can compare up to three models side by side, making it easy to find the ideal fit for your requirements.
But even without using this feature, you can easily deploy more than one model.
What is the limit of up to 1 million segments?
Model Studio is tailored to make the most of up to 1 million sentence pairs, in terms of both cleanliness and robustness. This limit applies to the data after de-duplication and potential corrupted characters suppression.
Please note that it is also advised not to upload very big files at once to avoid network issues.
How are markup tags handled in the training data?
At the moment, the handling of tags and placeholders can be challenging. Long sentences containing tags may be deleted to improve processing. However, we’re actively working on solutions to better handle tags, and this feature is expected to be available in 2024.
In the meantime, you can enter your tags into your CatTools and let these CatTools handle them.
Should training data be anonymized?
As seen before, and as placeholders may be considered as tag, using placeholders to anomymise data can be diffcult to handle.
Training data should be anonymized using “XX” instead of placeholder or tags.
This prevents ensure privacy and compliance with Data Protection Regulations. Rest assured, SYSTRAN prioritizes customer data security, and the platform has robust safety measures.
For instance, we have an automatic training data deletion feature, adjustable at the dataset level. The default value is set to 90 days, but we also offer options for 180 days and never deleting the data. It is possible to change this value after the upload.
How is the data cleaned after upload?
Automatic data cleaning is performed during the upload and during processing.
The data undergoes two major cleaning steps.
Firstly, duplicates in both source and target segments are removed. Secondly, we work on resolving wrong encodings and eliminate empty sentences from the target or source.
Then during data processing, another filtering and cleaning takes places for mainly the wrongly aligned segments or a wrong language.
Join over +1000 companies using SYSTRAN
Expand your company and grow with SYSTRAN