USE CASE
Forensics & eDiscovery
SYSTRAN’s advanced language technology streamlines investigations by efficiently and securely processing massive volumes of data. This will allow your team to overcome language barriers while providing valuable insights for cross-border legal disputes and forensic process.
Trusted by Leading Brands


BENEFITS
Unlocking Forensic Insights with Swift Machine Translation
Examining large data sets becomes challenging in complex international cases where multiple languages can obscure vital evidence. Depending on Language Service Providers to translate extensive document repositories before analysis is impractical due to the urgency of investigative processes.
Efficiency is crucial for review teams, demanding a focused approach. The inherent ambiguity in multilingual documents increases the risk of missing crucial details, potentially undermining a case. Addressing these challenges is essential for achieving favorable investigative outcomes.

BENEFITS
Data Security & Compliance
When dealing with legal documents, you’re largely talking about highly sensitive pieces of data. You need robust NMT software capable of providing iron-clad security features and adequately protecting all data.
This is essential to the integrity of any legal team and to chain of custody. Translating your eDiscovery content through a secure NMT platform like SYSTRAN means remaining compliant and efficiently working
your case towards success.
SYSTRAN ensures end-to-end encryption and follows industry best practices to protect sensitive information throughout the translation process. Your forensic and e-discovery data remain secure and compliant with regulatory requirements.
INTEGRATION
Relativity Connector
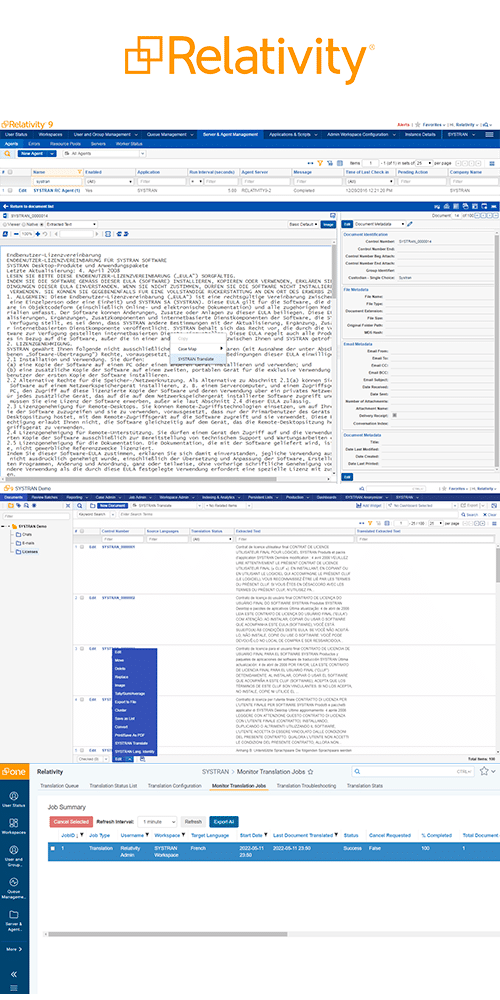
A robust MT solution must do more than have the ability to pass source code and process large files. It must have a native integration with a platform where eDiscovery is already happening. Relativity, an excellent document review platform that works closely with eDiscovery, is the preferred choice of many professionals to process multilingual content, especially in litigation scenarios.
SYSTRAN has expanded its capabilities by offering both on-premise and SaaS-based machine translation for RelativityOne.
These cloud-compatible connectors enhance the existing portfolio of on-premise Relativity connectors, facilitating efficient e-Discovery translation by scaling and translating globalized data. This extension empowers Relativity customers with the performance, security, scalability, and flexibility of cloud technology.
In addressing the challenges posed by the growth of Electronically Stored Information (ESI) and evolving legal standards, SYSTRAN’s technology tackles the complexities of Languages Other Than English (LOTE) documents, ensuring the confidentiality of e-Discovery procedures.
Managing Director, Alvarez & Marsal
“A key reason of using SYSTRAN was the depth of the integration with Relativity […] the speed and accuracy of the translations were impressive against other providers.”
Phil Beckett
BENEFITS
Enhanced Collaboration & Global Reach

Integrated with all the tools you need
SYSTRAN easily integrates with all your major applications, allowing for accurate, instant language translation to uncover the right information at the right time. Review teams can translate and analyze massive amounts of documents in seconds, no matter the language.
SYSTRAN allows your company’s core message to resonate in up to 55 languages.
- Marketing & Advertising
- Content Marketing Translation
- Conference Interpretation
- Pitch Book Translation
- Video Subtitling / Dubbing
- eCommerce Localization
- Business Meeting Interpretation
- Social Media Translation
- Website Localization
- Packaging Translation
- RFP Translation
- Sales Aid Translation
- Press Release Translation
- Market Research Translation
- Advertising Transcreation
How we solved our clients major issues


Discover the latest news & technologies




The winning strategy for your business Machine Translation: LLMs vs Specialized AI
Join over +1000 companies using SYSTRAN
Expand your company and grow with SYSTRAN