
Over decades, the translation industry has been proposing the use of “similar” translations in CAT tools, allowing human translators to visualize one or several matches retrieved from a translation memory (TM) when translating new documents. A translation memory (TM) is a database that stores segments of text and their corresponding translations. Segments can be sentences, paragraphs or sentence-like units (headings, titles, elements in a list, etc.). While the ideal situation is to find perfect matches, these are not always available. In such a case, translators resort to matches showing sufficient content in common with the document to be translated. These partial matches are then slightly “repaired” to achieve correct translations.
The use of TM matches relies on the idea that repairing a given TM match requires less effort than producing a translation from scratch, thus leading to higher productivity and consistency rates. The following figure illustrates human translation via repairing a TM match. The English sentence How long does the flight last? is translated into French considering the TM match How long does a flu last? — Quelle est la durée d’une grippe?
Following the next steps:
- Identify mismatches between input sentence and TM match: the flight — a flu (une grippe).
- Translate in context the missing sequence of the input sentence: the flight — le vol.
- Integrate the translation of the previous missing sequence into the TM match to complete the translation of the input sentence. Integrating usually involves discarding mismatches in the TM match: une grippe, checking word agreement and verifying the overall meaning of the resulting translation: le vol — du vol.

In past, TM matches have been seamlessly integrated into Statistical MT (SMT). Both, SMT and the repairing process follow the same simple idea of composing translation via an optimal combination of arbitrary long translation pieces. In contrast, the integration is less obvious in the case of Neural Machine Translation (NMT) since translation networks do not keep nor build a database of aligned sequences, and they operate over a distributed representation of words rather than discrete units.
Our work shows how we can exploit a TM by teaching a NMT model to integrate similar translations in the same way that a human considers TM matches. Furthermore, we evaluate different methods to retrieve “similar” sentences.
Measuring sentence similarity
Many methods to compute sentence similarity have been explored in the past, mainly falling into two broad categories: lexical matches (i.e. fuzzy matching) and distributional semantics. The former relies on the number of word overlaps between the sentences taken into account. The latter counts on the generalization power of neural networks when building distributed vector representations. The next figure illustrates similarity of sentence: How long does the flight last? (a) to two sentences: How long does a flu last? (b) and Which is the duration of the flight? (c) following fuzzy matching (left) and distributed vector representations (right).
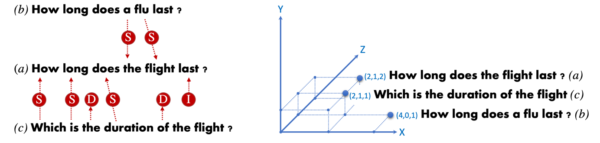
Notice that following sentence distributed representations, sentence (c) is closer to (a) than sentence (b). This approach notices the semantic similarity between How long does last and Which is the duration of despite not sharing any word. Fuzzy matching distance is computed by measuring the number of (S)ubstitutions, (I)nsertions and (D)eletions needed to convert one sentence into the other. In the case of distributional semantics, the cosine distance between sentence vector representations is typically used.
Priming Neural MT with TM matches
Priming is a well known and studied psychology phenomenon based on the prior presentation of one stimulus (cue) to influence the processing of a response. The next figure illustrates human priming. The human must predict the full form of a word that misses one letter so_p. Without priming (left) the human considers two options as equally likely, soap and soup, while after being primed with words in the semantic field of “foods” (right) the human considers more likely the word soup, which also belongs to the same semantic field.
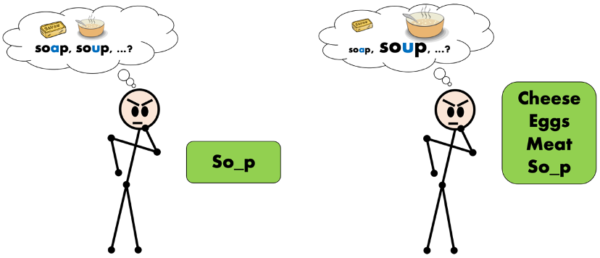
Our work follows a similar strategy to prime a neural machine translation network with similar translations obtained from a TM. We employ the similarity measures previously detailed and evaluate several approaches to prime the network at inference time, without adapting the network parameters.
Let’s first consider how translation is performed by an NMT network following the Transformer architecture. The next figure illustrates a simplified version of the translation inference for the input sentence How long does the flight last?

The initial encoder module is responsible for building the embedding representation of the input words, thus encoding input words into input vectors (grey blocks). Once the entire input sentence is read, the decoder module performs word-by-word generating the translation hypothesis. Notice that when generating translated words, the decoder pays attention to input words (grey arcs) as well as previously translated words (green arcs). This attention mechanism aims to focus on specific words that most notably contribute to the generation of the next translation word. A particularly useful technique for longer sequences
We now detail different ways to inject priming cues (TM matches) into the Transformer network. The first scheme is presented by (Bulté and Tezcan, 2019) and modifies the input stream by concatenating the similar translation found on the TM match to the input sentence. Therefore, the resulting input stream consists of two sentences each in a different language. The figure below illustrates the scheme. The decoder has now access to the TM match (blue arcs), which guide the decoder when generating target words.

The approach obtains important accuracy gains when similar sentences are available in the TM. However, a deficiency is also observed concerning unrelated words. We refer to unrelated words as those words of the TM match that must not be used in the translation (in our previous example d’ une grippe are unrelated words). In some cases, the translation network gets confused and copies also unrelated words in the current translation. The problem is particularly important when unrelated words are semantically close to the words of the right translation. Imagine for instance when translating the input stream:
![]()
Despite being an unrelated word, voyage [trip] is semantically close to the correct translation of flight, vol, and its apparition in the source stream encourages the network to use it in the translation of the input sentence.
In (Xu, Crego and Senellart, 2020) we proposed the first solution for this problem. It consists of using a second input stream (feature) to inform the network of the nature of each word: word of the input sentence (0); word of the TM match related to the input sentence (1); and word of the TM match not relevant to translate the input sentence (2)

Each stream is encoded in its own vector representation which are then concatenated to obtain a single vector for each input word. The rest of the network remains unchanged. Our results indicate a clear reduction in number of unrelated words appearing in translations.
In (Pham, Xu, Crego, Senellart and Yvon, 2020) we follow another scheme to inject priming cues in the Transformer network. Aiming at further alleviating the unrelated words problem we now indicate to the network both sides of the TM match. We concatenate the match source-side to the input sentence while the match translation-side is now passed to the network in the form of a decoder prefix (blue). The prefix is imposed to the beam search that performs in forced decoding mode. The next figure illustrates this scheme. The decoder produces the translation (green) paying attention to the TM match source words in addition to the TM match translation words (blue arcs) and input sentence words.

This scheme obtains the best translation accuracy results and further reduces the use of unrelated words of previous schemes. Using both match sides, we facilitate the network learning which similar words (blue) are needed when translating the input sentence. Note that this scheme allows to separate the encoder and decoder vocabularies.
More details can be found in the result table below and in the referenced papers. This research work is paving the way to deep integration of neural machine translation and CAT tools used by professional translators. Our engineers are now working hard for this feature to be available for all our users.
References:
- Neural Fuzzy Repair: Integrating Fuzzy Matches into Neural Machine Translation. Bram Bulte, Arda Tezcan. ACL 2019.
- Boosting Neural Machine Translation with Similar Translations. Jitao Xu, Josep Crego, Jean Senellart. ACL 2020.
- Priming Neural Machine Translation. Minh Quang Pham, Jitao Xu, Josep Crego, Jean Senellart, François Yvon. WMT 2020.





